Les principaux assistants intelligents du marché peuvent être dupés par un système qui leur envoie des commandes vocales sous la forme d'ultrasons inaudibles à l'oreille humaine. Six chercheurs chinois ont publié le résultat de leur expérimentation qui a su déjouer Siri, Alexa d'Amazon, Cortana de Microsoft, Google Now, S Voice de Samsung, HiVoice de Huawei et celui embarqué dans un Q3 d'Audi [pdf].
La méthode, baptisée en forme de clin d'œil "DolphinAttack", consiste à créer et utiliser un enregistrement audio de synthèse (dans le cas présent émis par un Galaxy S6) puis à le moduler pour le transmettre dans une fréquence supérieure aux 20 kHz imperceptibles par l'oreille humaine, mais que la cible électronique percevra.
L'équipe a testé son attaque vers différents iPhone depuis le 4s jusqu'au 7 Plus, des Nexus, Honor, MacBook, iPad, ThinkPad, Apple Watch ou encore Chrome sur un iPhone, l'enceinte intelligente Alexa et cette Audi vendue sur le marché chinois.
Une poignée de commandes ont été évaluées pour successivement réveiller l'assistant (par un "Dis Siri", "Ok Google", "Hi Galaxy", etc) puis lui donner des ordres. Ceux-ci comprenaient un numéro à composer par téléphone (ou par FaceTime sur iOS), l'ouverture d'une adresse web (Open dolphinattack.com), l'activation du mode avion, l'ouverture de la porte d'un domicile connectée avec Alexa et un ordre de conduite pour l'Audi.
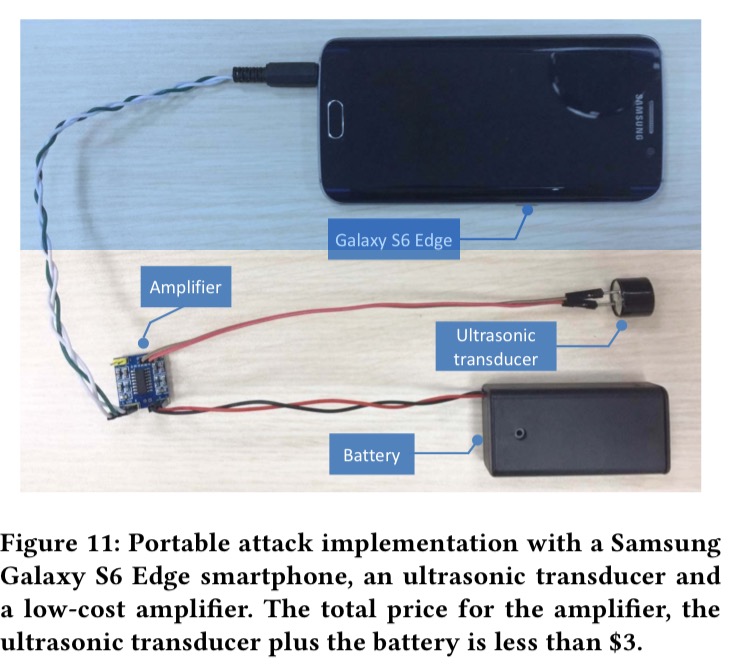{kind=link}
Chacune de ces actions a potentiellement un pouvoir de nuisance si la cible n'est pas consciente de l'attaque en cours ni en train d'utiliser son téléphone : envoyer un terminal sur un site web capable d'exploiter une vulnérabilité inconnue ; provoquer un appel audio/vidéo pour capter l'environnement immédiat de sa victime, créer puis envoyer un faux message par SMS, couper toute communication via le mode avion, etc. Il y a de quoi pimenter un scénario de thriller.
À l'exception de l'iPhone 6 Plus pour le réveil de Siri, tous ces appareils sont tombés dans le panneau. Trois commandes testées en anglais, français, chinois, espagnol et allemand ont donné des résultats homogènes et excellents en termes de fiabilité de la reconnaissance.
{kind=link}
Comme de trouver la distance idéale entre l'émetteur du signal sonore et sa cible. Cela varie d'une génération d'iPhone à l'autre et a fortiori entre un téléphone et une montre. Il faut par exemple 1m 75 maximum de distance pour un iPhone 4s mais 30 centimètres avec un iPhone SE. C'est encore différent sur ce même iPhone SE lorsqu'on veut passer par Google Now via Chrome où il faut diviser la distance par deux.
Ajoutez à cela que toutes les fréquences ne se valent pas, il faut en tester plusieurs, et que la capacité de reconnaissance varie en fonction du bruit environnant et de la longueur de la commande. Envoyer un "Dis Siri" dans l'environnement sonore d'une rue peut marcher à 90 % mais on chute à 30 % avec une phrase plus longue comme celle pour demander d'activer le mode avion.
Il faut tenir compte du retour vocal ou visuel de ces assistants lorsqu'ils ne comprennent pas la requête ou qu'ils l'exécutent. Cela peut attirer l'attention de la victime. Et certains scénario comme celui de forcer Alexa à ouvrir une porte sont par nature difficiles à mettre en oeuvre s'il faut déjà être dans la maison à proximité de l'enceinte…
Les chercheurs ont tout de même démontré qu'ils avaient pu franchir l'obstacle de l'identification de la voix du propriétaire de l'appareil sans quoi l'assistant ne répond pas. Cela peut se faire en testant de multiples combinaisons de voix de synthèse pour générer les commandes (ils ont opté pour un moteur de traduction vocal de texte de Google) ou, si l'on est en possession de fragments audio de sa victime, en étudiant les phonèmes des mots dont on dispose pour reconstituer les termes dont a on a besoin. Un travail de patience et d'orfèvrerie.
Des solutions existent pour les fabricants qui voudraient se prémunir de ces failles, explique l'équipe. D'abord par le matériel, en choisissant des microphones qui seront incapables d'entendre ces ultrasons, ou de les détecter pour mieux les ignorer. Par le logiciel ensuite, les systèmes d'exploitation devraient savoir analyser le signal audio reçu et faire la distinction entre une voix originale et une autre de synthèse.
Pas mal de contraintes au bout du compte pour organiser et mener à bien une telle attaque mais sa faisabilité a pu être démontrée.