Traçage : le Royaume-Uni choisit finalement l'API Apple/Google, carton plein pour l'app allemande
Suite, et sans doute pas fin, de notre palpitant feuilleton sur les grandeurs et misères des applications de traçage des contacts. L'API Exposure Notification pourrait bien avoir enregistré un nouvel utilisateur : le système de santé britannique, le NHS, a finalement choisi la boîte à outils développée par Apple et Google, selon la BBC. Un revirement spectaculaire de situation, le NHS ayant d'abord tout misé sur un modèle centralisé à la StopCovid.
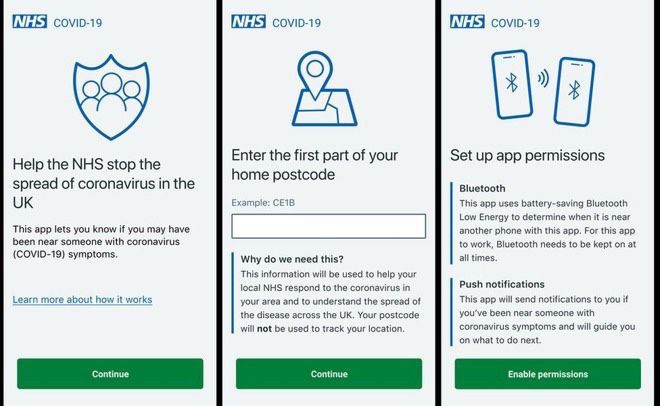
Après être parti très tôt par rapport à d'autres pays européens (les premières expérimentations grandeur nature de l'app NHS COVID-19 ont démarré début mai), le développement de l'application s'est embourbé dans les polémiques et les controverses, notamment en matière de collecte des données et de fonctionnement. L'hypothèse d'un changement de moteur en faveur de l'API commune a été rapidement envisagée, mais la transplantation demande du temps. C'est d'ailleurs un ancien dirigeant d'Apple, Simon Thompson, qui va superviser le développement de l'app avec l'outil Exposure Notification.

Alors que les Anglais devront attendre encore un moment avant de pouvoir installer leur app de traçage des contacts, les Allemands sont manifestement ravis de Corona-Warn-App, développée avec l'API Apple/Google. Disponible depuis deux jours, elle a atteint 7,9 millions de téléchargements ! Un succès d'autant plus méritoire que le débat a été vif outre-Rhin sur la confidentialité des données.
Le contraste est saisissant avec StopCovid, qui a atteint 1,7 million d'activations depuis le 2 juin, selon le dernier pointage de Cédric O. Le secrétaire d'État au Numérique, qui a porté le projet à bout de bras avec ses amis de l'Inria, a convenu que l'utilité de l'application est limitée en raison du nombre faible de nouveaux cas de contamination enregistrés ces derniers jours en France.
Le choix du Royaume-Uni de l'API Exposure Notification va isoler un peu plus la France dans son choix d'un modèle centralisé. 17 pays européens, plus le RU donc, sont dans le même bateau, ce qui va permettre aux différentes applications de communiquer entre elles comme le souhaite la Commission européenne. Une interopérabilité qui a du sens alors que les frontières intra-européennes sont en train de s'ouvrir pile pour l'été.







@webHAL1
Non.
Mais une app Google / Apple peut dire « vos données personnelles sont traitées sur votre smartphone » ou « la géolocalisation de votre appareil est impossible ».
@FloMo
Car l'application française StopCovid peut géolocaliser les appareils de ses utilisateurs ?
@webHAL1
Son accès au GPS n’est pas bloqué. Il n’est pas utilisé, mais peut l’être. D’ailleurs, sur Android, l’app demande l’accès à la géolocalisation en disant « promis, on ne l’utilise pas ». Le genre de message rassurant pour l’utilisateur 😂
@FloMo
Vous n’avez pas répondu à ma question ?
La version Apple / Google est elle sans risque ?
La réponse est catégoriquement non contrairement à vos affirmations.
On est pas risque 0 d’un côté et risque 100 de l’autre comme vous osez le sous entendre.
@francoismarty
A priori Didier Lallement n’est pas connecté aux api Google/Apple...et ces sociétés n’ont pas de police politique par chez moi.
@Steve Molle
Sacré Steve :)
@francoismarty
Non mais il faut sans cesse te rappeler des évidences
@Steve Molle
Je ne fais pas de politique ici.
@francoismarty
Ce n’est pas de la politique, c’est une réalité.
@FloMo
Ah ? Si quelqu'un installe l'application StopCovid sur son iPhone, elle aura automatiquement accès au GPS sans que l'utilisateur ne l'ait autorisé ?
@webHAL1
L’autorisation sera demandée. Mais là n’est pas la question.
Si l’accès au GPS est bloqué par le système, c’est une garantie absolue de ne pas avoir accès aux données de géolocalisation. Y compris en cas de piratage.
@FloMo
J'adore ce genre de démonstration.
- « Le truc aura accès à ta localisation ! »
- « Sans que je l'autorise et que je le sache ?! »
- « Non, mais bon, tu vois quoi, en cas de piratage, ou si on te vole ton appareil, ou s'il y a une méga-faille de sécurité iOS qui touche toutes les applications dont le nom commence par "stop" et finit par "covid", ou si tu postes sur les réseaux sociaux où tu te trouves, ou si tu as téléchargé StopVitvite au lieu de StopCovid, ben voilà, il y a un risque ! »
@webHAL1
C’est en générale comme ça que se passe la plupart des attaques informatiques sur mobile.
Je vais pas refaire l’historique, mais il suffit de prendre un moteur de recherche.
Et c’est d’ailleurs dans les recommandations OWASP pour la sécurité des apps mobiles. Et on peut dire que OWASP connaît son sujet.
D’ailleurs, j’ai moi-même été le premier à en douter. Mais voici comment j’ai procédé. Je suis allé sur le site OWASP. J’ai lu leur guide. J’ai testé les attaques proposées.
C’était il y a quelques années, donc le guide a dû évoluer. Mais les principes de précautions restent les mêmes.
Chaque développeur a d’ailleurs accès à un fichier Excel qui est une checklist permettant d’évaluer son niveau de sécurité.
Et ça va d’ailleurs bien plus loin que les préconisations d’Apple.
Je pense que dès que ça touche de près ou de loin à la santé, à la finance et à un certain niveau de vie privée, ces règles devraient être appliquées à la lettre.
@FloMo
C'est sûr que les attaques informatiques sur mobile sont un problème. J'imagine donc que, pour minimiser au maximum les risques, il est préférable de faire en sorte que les données ne restent pas stockées sur le téléphone portable lui-même, mais sur un serveur géré par des experts.
@webHAL1
La donnée transite forcément par le mobile à un moment donné. La question est de savoir s’il faut ajouter un vecteur de risque.
Et là-dessus, il y a 2 règles basiques en termes de protection des données et de sécurité.
La première est de mettre plusieurs barrières pour protéger la donnée. Ainsi, cela oblige à trouver plusieurs failles afin de réussir une attaque. C’est le fameux principe de Vauban, s’inspirant de nos architectures militaires.
L’autre règle est de minimiser les vecteurs de risque. Notamment en minimisant la quantité de données sensibles qui sortent des appareils. Et s’assurer que cet usage est indispensable.
Ainsi, il est plus sécurisé de laisser les données sensibles là où elles sont produites plutôt que de les faire naviguer entre plusieurs machines via de multiples canaux.
Cette recommandation de minimisation des données fait d’ailleurs partie du RGPD.
@FloMo
1. Il est impossible avec une application de traçage de ne pas avoir de serveur central, et donc de faire transiter des données. C'est d'ailleurs ce que beaucoup de personnes semblent ne pas comprendre lorsqu'on parle d'approche "décentralisée". Elle implique aussi un serveur, sur lequel des données seront collectées.
2. Il y a un terme important dans votre commentaire : sensibles. Des données anonymisées ne sont pas "sensibles". Une donnée est "sensible" à partir du moment on peut l'exploiter. De plus, dans les données collectées, les plus sensibles sont celles indiquant une personne infectée. Et celles-ci remontent au serveur quelle que soit l'approche choisie. Le fait de savoir que Monsieur Tartampion a passé 15 minutes à moins d'un mètre de Madame Michu n'a absolument aucune valeur, même si on pouvait identifier ces deux personnes (ce qui n'est pas le cas). Le fait de savoir que Monsieur Tartampion est atteint de la COVID-19, si on peut obtenir cette information (ce qui, pour l'instant, n'est qu'une hypothèse, que ce soit avec une approche centralisée ou décentralisée) est potentiellement problématique.
@webHAL1
1. L’approche décentralisée ne transmet pas les pseudonymes (juste les clés de chiffrement et horaires de validité) contrairement à l’approche centralisée
2. Les pseudonymes sont des données sensibles au sens du RGPD
D’ailleurs, le communiqué gouvernemental expliquant que les pseudonymes Apple transitaient d’appareil en appareil via le web (sic) et que cela revenait à faire transiter un diagnostic médical.
@FloMo
1. C'est faux pour l'approche centralisée. Plusieurs personnes vous l'ont déjà signalé, dont SyMich ayant participé au développement de StopCovid. Je vous le confirme : quand on se base sur des mensonges, il est compliqué de se faire une opinion objective.
@webHAL1
Comment ROBERT peut faire un diagnostic sur serveur sans ces données ? C’est impossible. Et le code source le confirme.
https://gitlab.inria.fr/stopcovid19/robert-client-api-spec/-/blob/develop/openapi.yaml
@FloMo
C'est tout à fait possible. Et le code source le confirme.
Hé, tiens, ça marche aussi. C'est fou.
Rappelez-moi, vous êtes développeur et vous avez analysé la totalité du code source, c'est bien ça ?
@webHAL1
Je suis développeur mais je n’ai pas analysé tout le code. Ça ne sert à rien d’analyser tout le code une fois que l’élément recherché est trouvé.
@FloMo
Et où se trouve-t-il, cet élément ?
@webHAL1
https://gitlab.inria.fr/stopcovid19/robert-client-api-spec/-/blob/develop/openapi.yaml
Ce sont les spécifications du service.
Objet RegisterSuccessResponse
> Tuples of identifiers to be used by the app during the epochs
ReportBatchRequest - contacts
@FloMo
En quoi cela démontre-t-il que des identifiants sont envoyés au serveur qui permettront d'identifier le possesseur de l'appareil ?
@FloMo
> Ainsi, il est plus sécurisé de laisser les données sensibles là où elles sont produites plutôt
> que de les faire naviguer entre plusieurs machines via de multiples canaux.
C'est faux.
Si l'endroit où elles sont produites comportent une surface d'attaque plus grande que celles des autres machines, ce n'est pas le cas. L'aspect "cela reste local" n'est pas, *en soit*, une meilleure sécurité, non.
Maintenant, la question est de savoir si la surface d'attaque d'un iOS ou d'un Android est plus grande que celle des serveurs d'une solution.
> Cette recommandation de minimisation des données fait d’ailleurs partie du RGPD.
Des données à caractère personnelles.
On en est loin ici. La donnée la moins personnelle dans les solutions actuelles, c'est l'adresse IP du smartphone quand il contacte le serveur de la solution.
La liste des pseudo-identifiants éphémères d'une durée de vie de 15 minutes se qualifieront difficilement de données "personnelles", d'autant qu'elles proviennent de données *reçues* d''autres appareils.
Que ces pseudo-identifiants soit des clés pour déchiffrer les détails attachés à leur réception ou pas ne change pas grand chose ici.
Et pour rappel, pour savoir si quelqu'un a choper le Covid, c'est simple : utiliser un téléphone dédié à cela quand vous rencontrez cette personne. Là, vous serez sur. API décentralisée ou pas. RGDP ou pas.
@byte_order
Le smartphone est un lieu de passage obligé. Quel que soit le protocole.
Tout ce qu’on ajoute en plus pour promener les données expose à un risque.
Et le risque est encore plus grand si ces données sont sensibles.
@FloMo
Oui, mais n'affirmez pas que le fait que des données restent locales sur une machine augmente leur sécurité. Tout dépend de la qualité des barrières de ladite machine.
On peut très bien avoir plus de facilité à accéder à des données stoquées localement sur une machine que des les intercepter durant leur transport ou leur éventuel stockage sur l'autre machine destinatrice.
D'ailleurs, la durée de conservation d'une donnée est en soit un critère de risque.
Un traitement qui conserve en mémoire que très peu de temps des données, par exemple, laisse peu de temps pour intercepter la donnée.
Merci de ne pas sortir une généralité "donnée locale = plus sûre", car c'est absolument pas vrai.
@byte_order
C’est une évidence que c’est plus sûr.
Si on simplifie, on peut dire (par exemple) :
- 5 failles sur l’appareil
- 2 failles sur le réseau WiFi
- 1 faille sur le serveur.
Si je centralise, j’ai 8 failles.
Si je décentralise, je n’en ai que 5.
Même si au global il y a moins de failles hors de l’appareil.
@FloMo
Ah, parce que pour vous toutes les failles offrent la même surface d'attaque !?
> Si je centralise, j’ai 8 failles.
Dont 5 locales.
> Si je décentralise, je n’en ai que 5.
Dont 5 locales.
Sur la surface d'attaque de ces 5 failles locales est supérieure aux 3 autres, vos données locales ne sont pas plus sûres, non. Le fait que des données restent locales n'est pas en soit une meilleure sécurité, c'est faux d'affirmer cela.
@byte_order
Les failles locales seront exploitables dans tous les cas vu que c’est un passage obligé.
Par contre, aller balader ces infos sur des serveurs, ce n’est pas indispensable.
@FloMo
> Par contre, aller balader ces infos sur des serveurs, ce n’est pas indispensable.
Cela l'est si l'on ne veut pas qu'un diagnostic de santé soit fait par une boite noire sous contrôle exclusive d'une entreprise étrangère.
Après, rien n'empêcherait Apple/Google de proposer une API qui permette ce qui était réellement nécessaire, c.a.d l'écoute passive du BT en tâche de fond, l'entretien de tokens éphémères, de la liste de ceux croisés, mais qui laisse l'app implémenter elle même, de façon souveraine donc, ce diagnostic.
@byte_order
Le diagnostic est configurable.
Son implémentation ne peut pas être « libre » car en cas d’attaque de l’app, le runtime pourrait générer des faux positifs.
Là, c’est cloisonné.
@FloMo
> Le diagnostic est configurable.
Paramètres vs algo. Pas comparable.
> Son implémentation ne peut pas être « libre » car en cas d’attaque de
> l’app, le runtime pourrait générer des faux positifs.
Hein ???
Donc OpenSSL étant d'implémentation libre, c'est pas fiable !?
N'importe quoi. Le bon vieux open source pas sûr, proprio plus sûr.
Désolant...
> Là, c’est cloisonné.
Par une entreprise étrangère.
@byte_order
On tombe dans l’idéologie là où il faut du pragmatisme. C’est bien dommage.
@byte_order
Ha bah si c’est souverain, on s’en fout de la sécurité des données personnelles ! 😂
@FloMo
Où avez-vous vu qu'ils s'en foutaient !?
Ils ne protègent pas le transfert des données ?
Ils ne vérifient pas que le serveur est bien celui attendu (certificate pining) ?
Les serveurs sont open-bar !?
Aucun audit de sécurité n'a été fait ?
Aucune correction n'a été faite concernant la sécurité ?
Et de l'autre côté, que savez vous vraiment de la réalité de la sécurité dans la boite noire de l'API ?
Qu'avez-vous comme moyen de vérifier que les données seront bien détruites par la boite noire ?
Apple et Google n'ont jamais été pris en défaut, même involontaire, en matière de protection de données ? Jamais ?
Dans les 2 cas c'est au final qu'un choix de qui on accorde sa confiance le plus.
Vous accordez visiblement plus confiance à une entreprise étrangère qu'à une entreprise française.
Le pragmatisme, c'est justement de ne pas partir de préjugés, comme "données restant en local = automatiquement plus sûr", "entreprise privée forcément meilleure qu'un projet public", "proprio plus sûr que open source", etc !
Ca, c'est plus de l'idéologie, justement.
@byte_order
Les données uniquement en local sont plus sûres. C’est une évidence. La majorité des chercheurs en sécurité est d’accord sur ce point.
C’est ce qui a amené l’Europe à choisir l’approche décentralisée. (Sans spécifier A/G, mais une approche décentralisée)
Et la France a privilégié la souveraineté au détriment de la sécurité en ne mettant pas en œuvre ce qui avait été voté.
On verra si ce choix a été pertinent. Mais, à date, on ne dirait pas.
Après, ce n’est pas aujourd’hui qu’on peut se prononcer. Aujourd’hui, en théorie, les 2 systèmes sont bons.
Sauf qu’il y en a un qui fonctionne uniquement dans un seul pays. Et la majorité des autres sont facilement interopérables.
> Les données uniquement en local sont plus sûres.
> C’est une évidence. La majorité des chercheurs en sécurité est d’accord sur ce point.
Ah.
J'ai des données personnelles uniquement sur ma machine.
Bon, j'ai un serveur FTP avec accès guest parce que j'y comprends rien en informatique. Ou parce que fiston a installer un malware sans le savoir.
Mes données personnelles n'étant stockées qu'en locales, je crains rien, hein ?
vs
J'envoi mes données personnelles chiffrées via une connexion SSL sur un serveur DropBox (ou même iCloud, tiens), rien ne reste en local.
Mes données locales sont vraiment les plus sûres, les moins exposées !?
Vous êtes vraiment sûr de ça !?
> Et la majorité des autres sont facilement interopérables.
A voir si les échanges entre serveurs de chaque solution de chaque pays seront mis en place.
@byte_order
> Ok. J'installe un FTP sur ma machine avec accès guest, et mes données personnelles ne sont que sur ma machine.
C’est l’exemple parfait.
Le FTP est en effet ouvert sur Internet. Ce n’est donc pas sécurisé.
On ferme le port FTP, on arrête le serveur.
Là, c’est sécurisé.
> A voir si les échanges entre serveurs de chaque solution de chaque pays seront mis en place.
Évidemment. Mais si ça parle le même langage, c’est plus facile. Et si les données échangées ne sont pas sensibles, c’est encore mieux.
@FloMo
> C’est l’exemple parfait.
Je trouve aussi.
> Le FTP est en effet ouvert sur Internet. Ce n’est donc pas sécurisé.
> On ferme le port FTP, on arrête le serveur.
Donc que les données étaient conservées que localement n'apportait _en soit_, de facto, pas une meilleure sécurité.
Puisque c'est en réduisant fortement la surface d'attaque de la machine (ici FTP) que leur sécurité remonte, alors qu'elles sont restées uniquement locales tout le temps.
C'est bel et bien la surface d'attaque de chaque machine qui compte. La durée pendant lequel on peut acceder aux données aussi, au passage, ce qui ne milite pas pour tout sockage persistent d'une manière générale.
@byte_order
La surface d’attaque augmente avec le nombre de supports.
@FloMo
Pas dans mon exemple, non : dans les 2 cas c'est exactement 1 seul et même support.
Ce qui a augmenté la surface d'attaque ici, c'est la taille de la faille de sécurité de ma machine, pas le nombre de supports. J'aurais pu copié ces données sur une autre machine, mais pas exposée sur Internet. 2 supports, même surface d'attaque.
La durée de persistance de l'info compte aussi, par exemple.
Mes données personnelles n'auraient eu une durée de vie que d'une seconde sur ma machine, par exemple, même avec un FTP ouvert, mes données personnelles étaient moins exposées que celles qui perduront longtemps chez DropBox, iCloud, même chiffrées.
@byte_order
Le durée de persistance compte en effet. Mais je crois que tout le monde est d’accord sur les 14 jours max.
Au-delà du débat actuel, je pense qu’Apple va proposer sa solution HealtKit pour centraliser les données.
HealtKit est open-source et hébergé par les labos.
Ça s’appuie sur du chiffrement de bout en bout.
L’intérêt est qu’on peut ajouter des informations issues de l’app santé (symptômes, données de la Watch et autres appareils) afin d’améliorer la connaissance de la maladie.
Et l’intérêt pour Apple est de vendre des Watch et améliorer son image de marque.
Mais sur l’aspect technique, c’est vraiment intéressant comme approche.
Et je pense que CoreML 3 permettra d’améliorer localement les modèles d’apprentissage automatique pour les centraliser de manière sécurisée / anonymisée ensuite.
@byte_order
Et les pseudo-identifiants éphémères sont des données personnelles au sens du RGPD. Car ça suffit à identifier une personne.
« L’analyse du protocole technique par la Commission confirme cependant que l’application traitera bien des données personnelles et sera soumise au RGPD. » (source CNIL)
@FloMo
Dans le même avis de la CNIL, juste au dessus y'a écrit :
"la CNIL reconnaît qu’elle respecte le concept de protection des données dès la conception, car l’application utilise des pseudonymes et ne permettra pas de remontée de listes de personnes contaminées."
Les données personnelles soumises à la RGPD, c'est l'envoie de son (propre) status de diagnostiqué positif, c'est l'identifiant unique (que je trouve dommage, perso) associé à l'app activé.
Par ailleurs, la RGPD n'impose nullement de ne pas les envoyé, elle dit que l'utilisateur doit avoir tout le temps le contrôle sur leur usage et qu'elles doivent être échanger de manière protégée, par chiffrement par exemple.
@byte_order
Sauf qu’en pratique, ça ne se passe pas vraiment comme ça. Et ça a déclenché une enquête récemment.
L’erreur est humaine. Mais le plus simple aurait été de ne pas prendre de risque.
Rien n’empêchait une approche décentralisée « souveraine ».
@FloMo
> Rien n’empêchait une approche décentralisée « souveraine ».
Si, le fait que la boite noire de l'API viole la souveraineté de diagnostique de santé.
Ce n'est pas à une entreprise etrangère de décider si un pseudonyme croisé a été exposé ou pas à un virus.
Sinon, la prochaine fois elle décidera si on est en bonne santé ou pas ?! Bonjour l'attractivité de l'info pour les assurances !
La boite étant noire, on ne peut pas vérifier ce qu'elle fait réellement des paramètres fournis, ni même de modifier la façon dont le diagnostique, ni si elle conserve finalement cette info, pendant combien de temps, ce qu'elle en fait réellement.
Ce qui a empêché l'usage de l'API, c'est l'aspect tout-ou-rien de cette API.
@byte_order
Oui. Mais une approche décentralisée est possible sans Apple / Google.
Après, c’est sûr qu’ils offrent une API. Ils vont pas non plus faire du sur mesure. Faut pas exagérer.
@FloMo
> Oui. Mais une approche décentralisée est possible sans Apple / Google.
Certes. C'est d'ailleurs ce qui aurait eu ma préférence : décentralisée mais souveraine.
> Ils vont pas non plus faire du sur mesure. Faut pas exagérer.
Ben tiens. Faudrait pas qu'elles participent bénévolement à la lutte contre une pandémie, hein, c'est pas leur responsabilité, elles ne sont pas dans la philantropie.
Mais leur confier une diagnostique de santé, par contre, là, pas de problème,
là elles vont faire l'effort.
@FloMo
> Mais une app Google / Apple peut dire « vos données personnelles sont traitées sur
> votre smartphone » ou « la géolocalisation de votre appareil est impossible ».
Mais ce ne sont pas des apps "Google" ou "Apple". L'éditeur indiqué est différent.
Et je doute fort que la majorité des gens qui installent ce type d'apps vont d'abord vérifier si Google ou Apple a collaborer et comment à la solution.
Les islandais ont massivement adopter la leur, par exemple.
Je ne pense pas que les islandais soient moins sensibles à la protection de leurs données personnelles que la moyenne, pourtant.
Pages