Apple A11 : en route vers un 10 nm plein de promesses
Que ce soit Samsung ou TSMC qui s'occupe de la production du prochain processeur mobile d'Apple, les deux sont prêts pour une gravure en 10 nanomètres, contre 14 au mieux actuellement.
Samsung a annoncé aujourd'hui avoir commencé la production de masse de systèmes sur puce (SoC) avec sa technologie FinFET 10 nm. Qui dit gravure plus fine, dit plus de transistors sur la même surface. En l'occurence, il y en a jusqu'à 30 % supplémentaire. Mais le plus parlant, c'est quand le géant sud-coréen indique un gain de performances jusqu'à 27 % et une consommation d'énergie réduite jusqu'à 40 %. Ça promet !
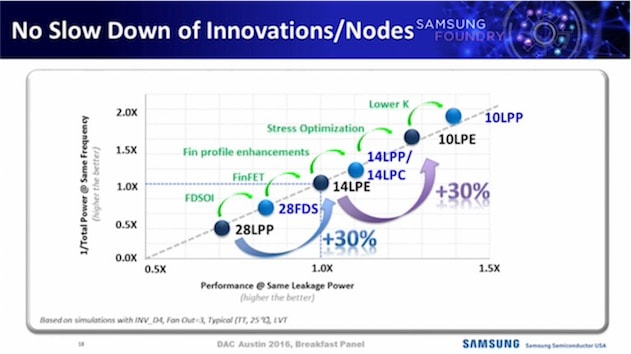
Les premiers appareils embarquant un SoC 10 nm sortiront en début d'année prochaine. Le Galaxy S8 en bénéficiera vraisemblablement. Samsung prévoit d'ores et déjà une révision de son processus de gravure en 10 nm (le « 10LPP » succédera au « 10LPE ») au second semestre 2017 visant à « booster les performances ».
Pour mémoire, l'A10 Fusion des iPhone 7 est gravé par TSMC en 16 nm comme l'A9 des iPhone 6s (sauf une partie des A9 qui est produite par Samsung en 14 nm, mais la différence à l'usage est imperceptible).
Ce serait d'ailleurs TSMC qui aurait de nouveau l'entière responsabilité du prochain SoC d'Apple. Le fondeur a récemment communiqué sa feuille de route qui est identique à celle de Samsung : mise en production du 10 nm au cours de ce trimestre et arrivée des premiers produits finaux début 2017.
TSMC a fait savoir que le 10 nm allait être réservé à ses très gros clients, dont Apple fait bien entendu partie. Les autres devront attendre le 7 nm, qui arrivera assez rapidement. Le plan est en effet de commencer la production à risque dès le premier trimestre 2017 (2018 chez Samsung).
Les deux principaux fondeurs du marché mobile ont depuis peu un nouveau concurrent de renom en la personne d'Intel. Le CEO de TSMC, actuel leader, estime que la prise de licence ARM par Intel va surtout renforcer ARM, même s'il ne sous-estime pas le potentiel du « nouveau » fondeur. D'autant qu'Apple et Intel seraient déjà en discussion à propos des futurs processeurs de l'iPhone...







J'ai hâte de commander mon iPhone 8 noir de jais 512 Go
@iVador :
512 go en iPad pro pour moi :)
@iVador :
Vise le S par defaut !
@iVador :
Quand ton MacBook Pro affiche 128go
eh oui... ;(
La battaille du 14nm a ete perdue, ses mirifiques promesses de puissance, d'autonomie, d'efficacité energetique,... sont tombées a l'eau et ne se sont revelées que des promesses electorale sans lendemain!
le x86 d'Intel continu de stagner avec energie, mais le taux de dechet en 14nm n'arrive pas a diminuer. Les ARM 16 et 14 nm, chauffent, plus que les precedents et le gain de puissance depend majoritairement de l'architecture!
AMD est toujours a la rue face a NVidia, mais il est vrai que Nvidia avait reussi a diviser par deux la consommation sur la gravure a 28 nm, et ne s'est pas laissé berner par la finesse prometteuse.
Surtout, il faut se rendre compte que le 14nm au lieu d'apporter un gain de rentabilité des lignes de production a infligé une surcharge de couts qui penalise toute l'industrie. Intel, societe multimiliardaire et reference a du annuler la construction d'usine en 14nm, trop couteuses et pas rentable.
Le 14nm est un echec cinglant, qui ne fait qu'officialiser la fin de la conjecture de Moore. Mais plutot que reconnaitre cette fatalité, et de mettre en avant l'architecture, qui demande du temps et des competences et du pragmatisme, tout ce petit monde fonce encore plus vite sur la nouvelle promesse electorale: le 10nm!
Ce sont les memes promesses que le 14nm, mais l'echec a attendre sera encore plus cinglant.
Dans ce nuage bien sombre fait de mensonges heontés et de promesses intenables, le seul element qui donne un petit espoir c'est l'amelioration du FinFET. Ce n'a rien a voir avec la finesse de gravure, mais ça a un impact positif sur la consommation des circuit. On pourrait revenir au 22nm, avec l'evolution du FinFET on aurait quand meme une amelioration de la consommation d'au moins 30%, mais uniquement au niveau du transistor! Faut pas rever, ça vapas faire -30% de conso pour le processeur!
@C1rc3@0rc :
Un gars qui parle de conjecture de Moore ne peut pas être tout-à-fait mauvais:-) ;-)
merci, mais je regrette d'avoir condensé et aurai du ecrire «dogme de la conjecture de Mooore» car si la conjecture de base reste juste une conjecture, et une hypothese parmi tant d'autres, le drame c'est que toute une industrie sous le joug de la finance en a fait un dogme économique qui a stérilisé des pans entier de la recherche et de l'ingenierie.
De la bombe bébé !
La diatribe de C1rc3@0rc ne devrait pas tarder ;-)
« Les autres devront attendre le 7 nm, qui arrivera assez rapidement. »
Wow, 7 nm ! Impressionnant tout de même.
non.
IBM a montre des transistors a bien plus petite echelle: en labo on peut faire encore moins depuis longtemps, mais pas avec du silicium.
Le seul exploit et la grande folie c'est de rester scotché sur le silicium pour ces finesses de gravure.
Faut rappeler que l'avantage premier de la finesse de gravure c'est d'augmenter la rentabilité... du fondeur.
Plus on grave fin, moins y a de materiaux a utiliser, donc ça coute moins cher a produire... jusqu'à une certaine limite qui semble avoir ete le 22 nm en industriel et pour le silicium. En descendant dessous, faut avoir des matériaux de bien meilleure qualité, ce qui coute plus cher, le taux de déchets augmente, ce qui coute plus cher, et surtout les dysfonctionnements lies aux problemes quantiques implique de compliquer le produit pour compenser ces dysfonctionnement, et qui dit complication, dit ralentissement et consommation d'energie...
On pourrait facilement graver a 5nm, ou moins, en simplifiant le produit et éviter les effets quantiques, mais faudrait passer a d'autres matériaux que le silicium. Pourquoi on utilise le silicium, malgre ses inconvenients alors? Parce que c'est abondant et pas cher!
On est pas sur un problème technologique, mais sur un problème financier. Le fondeur est un industriel dependant du systeme financier! Il doit augmenter ses marges deja tres confortables. Passer a un autre materiaux voudrait dire faire de reels progrès technologiques, mais ça impliquerait une fonte des marges des fondeurs...
Et c'est cette dependance a la finance speculative qui est impressionnante!
@C1rc3@0rc :
Comment sais-tu que les alternatives au silicium soi disant bien meilleures que les processeurs actuels sont prêtes pour une utilisation industrielle dès maintenant ?
Tu es chercheur en systèmes logiques ?
À moins que tu n'affirmes des choses injustifiées ?
Tous les acteurs du marché sont prêts à investir des milliards pour ensuite devenir le meilleur fondeur et avoir le monopole. Dans un autre domaine, Samsung a énormément investi dans l'OLED par exemple alors que cette technologie était très chère et pas encore mâture, pour aujourd'hui avoir le quasi monopole dans ce domaine. Si Samsung connaissant une alternative au silicium qui pouvait déjà être produite en masse, la production aurait déjà commencé...
@sachouba :
La rupture entre un LCD et un oled n est pas la même qu entre les technologies basé sur le silicium et l or et celle par exemple qui utiliserais le graphene.
On connaît bon nombre d alternatives a l emploi de produits issus du pétrole dans bien des domaines pourtant le pétrole reste.
@sachouba
"Tu es chercheur en systèmes logiques ?"
Pourquoi il faut être chercheur uniquement pour pouvoir partager des informations ?
Il existe des revues spécialisées qui en parlent. On peut parfois répéter ce que l'on a appris ailleurs.
Par exemple je peux te dire que la lune est née suite à une collision d'un énorme corps céleste avec la terre naisante. Suite à cette collision, des matirères de la terre ont été projetées. Et en quelques millions d'années, ces matières se sont aglomérées pour constituer la lune. A la naissance la distance terre/lune était beaucoup plus proche qu'aujourd'hui. et bla bla bla...
Tu vois je ne suis pas du tout chercheur en astronomie... c'est juste que la semaine dernière il y avait une super émission sur la naissance de la terre. Je suis juste aussi un passioné en astronomie.
Toute fois il est probable aussi que @C1rc3@0rc soit un chercheur dans ce domaine
@XiliX :
Je n'affirme pas qu'il faut nécessairement être un chercheur pour partager ses connaissances, mais pour partager des connaissances qui ne sont disponibles dans aucune publication scientifique (du type : l'industrie est complètement prête à changer le silicium par d'autres éléments mais elle ne le fait pas car c'est un investissement), il est obligatoire d'avoir d'autres sources d'informations qui ne sont pas encore publiques (c'est le cas d'un chercheur, par exemple).
@sachouba
Ok je comprend mieux.
Mais il se peut aussi tout simplement que l'on ne sait pas, car on n'était pas au bon endroit et au bon moment pour obtenir ces informations.
@sachouba :
Sur ces questions il n'y a pas grand chose en terme d'état de l'art qui ne soit pas accessible.
C'est bien plus sur les enjeux économiques et stratégiques que les données de base sont difficile à trouver et l'état des lieux passe par l'inférence
C'est pas ça qui d'une certaine manière reprend la suite de la loi de Moore, avant d'être elle même bientôt bloquée à des limites physiques de finesses ???
@calotype :
http://www.tomshardware.fr/articles/transistor-loi-moore-miniaturisation-processeur,1-60558.html
Il y a quelques mois ils annonçaient 10 nm comme étant la limite, force est de constater qu'elle a été repoussée.
@tekikou :
Ooook ! Donc ça va graver en volume et même de façon transversale … heuuu ! D'accord ??? Des boucles ? Ils vont commencer à faire des boucles en gravure de processeurs ? Du tricot … quoi ^^
du tricot! oh c'est tres bon, merci pour ce mot d'esprit ;)
La limite du silicium a ete atteinte et demontré dans les labo de Grenoble avec le 18nm. Ça veut pas dire qu'on peut pas utiliser un ensemble d'artifice pour graver plus fin, mais ça veut dire que 18 c'est la limite sous laquelle les avantages sont nuls voire negatifs. Plus on descend sous 18 nm, plus y a de problemes, plus faut compenser, plus ça consomme, plus ça chauffe... donc ce que l'on gagne d'un coté on le perd de l'autre...
La taille d'un atome de silicium c'est 111pm, soit 0,111 nm.
Le plus petit transistor du monde utilisant le silicium etait en 2010 composé de 7 atomes! Beaucoup se sont enflammés en voyant cette finesse de gravure (en fait il s'agit plus d'impression 3D en l'occurence) en 2015 avec des surper ordinateurs capables de casser des code RSA en quelques secondes... oui, en 2015.
En 2012 une equipe americano australienne a produit un transistor avec un seul atome de phosphore dans un cristal de silicium (http://www.nature.com/nnano/journal/v7/n4/full/nnano.2012.21.html).
En théorie on peut donc reduire la taille d'un transistor jusqu'à ce que ses composants les plus petits a ne dépassent pas la taille d'un atome. En theorie.
Depuis l'industrie peine avec le 14nm, et la puissance des processeurs stagne méchamment. Pour casser RSA on compte plus sur les backdoor introduites par la NSA que sur Intel...
et coté ARM on voit la panique et le tsunami provoqué par Apple avec le passage en 64bits, 10 ans apres le PowerPC G5...
Le secret aujourd'hui de l'evolution des processeur, c'est le travail sur l'architecture. Les gains de consommation et de vitesse de traitement se font sur le travail sur l'architecture, mais cela prend du temps et demande des competences et c'est un produit de l'intelligence, pas de la mecanique, comme l'est la finesse de gravure...
Et l'avancée de l'informatique aujourd'hui passe par la competence du developpeur et du mathematicien.
Et ça la finance n'aime pas.
@C1rc3@0rc :
Juste par curiosité quel est ton métier dans la vie ?
@Dranouss
Parce que commentateur sur MacG, ce n'est pas un vrai métier peut-être ?
@nicolasf :
Non c'est un sacerdoce :-)
@C1rc3@0rc :
Merci pour toutes tes explications ' tres intéressant ! Tu devrais faire des articles pour MacG sur le sujet !!
@Patrick75 :
Attention quand même, il y a à boire et à manger.
@awk :
Bah écoute à le lire, ca a l'air censé et tout est clair (même moi j'ai compris)
C'est appuyé par des exemples et des sources.
Je vois pas quoi il dirait n'importe quoi.
C'est n'importe quoi quand C1rc3@0rc dit:
" le travail sur l'architecture, mais cela prend du temps et demande des compétences et c'est un produit de l'intelligence, pas de la mecanique, comme l'est la finesse de gravure..."
La finesse de la gravure c'est aussi bien un produit de l'intelligence que le travail sur l'architecture, contrairement à ce qu'il dit. Et c'est même un travail de plus en plus difficile qui nécessite des investissements extrêmement lourds en temps de développement et de production de machine et de locaux hyper propres.
D'ailleurs la finesse de gravure n'a rien d'un travail mécanique! Affirmer ça c'est carrément comique.
@Trillot
"D'ailleurs la finesse de gravure n'a rien d'un travail mécanique! Affirmer ça c'est carrément comique."
Si au lieu de l'insulter tu nous expliquait pourquoi la finesse de gravure n'a rien d'un travail mécanique ? je suis très curieux de connaitre la raison:
@Trillot :
Notre camarade aime les caricature et l'outrance.
Il n'en reste pas moins qu'il y a du vrai dans son propos.
L'application de la loi empirique de Moore a effectivement quelques choses de l'ordre de la mécanique et de l'approche en force brute.
Cela ne veut évidemment pas dire que ce travail n'implique pas de gros efforts intellectuelles, des défis, de l'inventivité...
Mais il n'est pas au même niveau de créativité pure que celui autour des questions de micro-architecture.
On pourrait résumer le point de vue ainsi : les enjeux de créativité conceptuelle pure s'efface devant une certaine force brute quand il s'agit de trouver les moyens de donner raison à Moore et à sa conjecture.
En caricaturant : c'est quand même assez bourrin même si ce n'est pas pour autant à la portée du premier con venue
@C1rc3@0rc :
Oui, ce serait sympa de savoir si ton expérience sur le sujet est professionnelle, tes commentaires sont intéressants mais suscitent des critiques de @awk par exemple.
@Gladjessca :
Oui enfin même le travail de Tim Cook est critiquée voir remis en cause sur iGeneration dans les commentaires .
@C1rc3@0rc :
"Le secret aujourd'hui de l'evolution des processeur, c'est le travail sur l'architecture. Les gains de consommation et de vitesse de traitement se font sur le travail sur l'architecture, mais cela prend du temps et demande des competences et c'est un produit de l'intelligence, pas de la mecanique, comme l'est la finesse de gravure..."
Hummm, pas vraiment. Si on prend en exemple les Ax d'Apple, les évolutions de performances sont surtout dues aux montées en fréquence (permises par la diminution de finesse, quoi qu'on en dise), et au travail sur les bus mémoires et les caches. L'architecture n'évolue presque pas. C'est la même chose chez Qualcomm.
Leurs licences ARM leur permettent de réaliser une belle optimisation (on devrait même dire une adaptation) de l'architecture, mais ça reste quand même assez trivial, c'est surtout du travail sur le pipeline, le power gating, ou encore l'asynchronisme des différents domaines d'horloge. Je ne sais pas si tu as déjà mis le nez dans du Cortex de dernière génération, mais ARM fait déjà un excellent job en amont. Du coup on optimise un bon coup, puis on pérennise en jouant sur la fréquence et les mémoires, en attendant la prochaine itération de chez ARM.
@Scalp
"Hummm, pas vraiment. Si on prend en exemple les Ax d'Apple, les évolutions de performances sont surtout dues aux montées en fréquence (permises par la diminution de finesse, quoi qu'on en dise), et au travail sur les bus mémoires et les caches. L'architecture n'évolue presque pas. C'est la même chose chez Qualcomm."
Bah si c'est aussi un travail sur l'architecture. Il ne suffit pas d'augmenter la fréquence. C'est comme si dans une maison, pour avoir un débit d'eau plus important il suffit d'installer un gros tuyeau. Non il faut aussi revoir les installations de la plomberie. Il y a des chaces que des modifications structurelles seront nécessaires afin de pouvoir caser les gros tuyeaux.
On ne parle pas ici de tuning, qui se fait en augmentant l'horloge en dehors de la puce, car la puce elle même a été prévue pour faire de l'overclocking.
Il ne suffit pas d'augmenter juste la fréquence pour avoir une puce plus performante si au final on a un goulot d'étranglement au niveau du traitement (mémoire, registres, pipelines, caches...etc). Il ne suffit pas d'ajouter des coeurs supplémentaires et ça roule. Il faut revoir aussi le controleur qui doit orchestrer les coeurs. L'accès sur les périphériques, mémoires, stockage... bref l'architecture quoi
Je suis d'accord avec toi que le "gros" du travail d'architecture est déjà là, néanmoins, cela reste un travail sur l'architecture de la puce.
Dans un SoC (et je parle bien du contexte de Cortex Ax/A5x), le premier réflexe pour augmenter la puissance de calcul est d'augmenter la fréquence du cœur. Ton fameux goulet d'étranglement, ce sont avant tout les caches, donc c'est la première chose que l'on va redimensionner, en modifiant éventuellement la gestion de cohérence des caches. Si tu as acheté l'option chez ARM, tu as de la marge. Donc pour l'instant il n'y a aucune modification d'architecture.
Le deuxième goulet, ça va être éventuellement le fetch de tes instructions/ bande passante de ta stack en mémoire externe. Là encore, pour gagner de la bande passante, on change soit de techno de mémoire, donc on achète le contrôleur ad-hoc que l'on plug tout simplement sur le bus (AXI dans notre cas), soit on augmente la taille du bus. Il n'y a toujours aucune modification d'architecture.
Et c'est exactement ce que font Apple,Qualcomm et Samsung ces dernières années (je ne l'invente pas, il suffit d'aller voir chez Chipworks, Anandtech et autres).
Chez Apple, le travail sur l'architecture (changement de pipeline, modification du prefetch, etc) a été fait quand il sont passés sur le 64 bits (donc plateforme A53).
Je ne parle pas du GPU, car là c'est vraiment une blackbox qu'on achète directement à un tiers et que l'on clock jusqu'à avoir la puissance (on n'a pas encore vraiment la problématique mémoire des énromes GPU de PC/consoles).
@Scalp
"Le deuxième goulet, ça va être éventuellement le fetch de tes instructions/ bande passante de ta stack en mémoire externe. Là encore, pour gagner de la bande passante, on change soit de techno de mémoire, donc on achète le contrôleur ad-hoc que l'on plug tout simplement sur le bus (AXI dans notre cas), soit on augmente la taille du bus. Il n'y a toujours aucune modification d'architecture."
Je reprends juste cet exemple car c'est très significatif. Donc selon toi, augmenter ne serait-ce que augmenter la taille du bus n'est pas un changement d'architecture ?
Modifier le contrôleur par un qui correspond à l'ensemble n'est pas un chagement d'architecture ?
Comme je disais dans mon exemple avec la plomberie, ce n'est pas parce que on ne change pas la maison, qu'il n'y a pas de changement d'architecture. Une architecture est un ensemble. Le fait de monter la bande passante que ce soit en changeant le(s) bus ou fréquence, nécessite un remodelage de l'architecture. Tu ne peux pas juste ajouter des "pistes" pour élargir le bus de données ou d'adresses. Il faut aussi modifier le contrôleur... etc..etc... Donc un changement d'architecture
@Xilix
En fait on diverge juste sur la notion de changement d'architecture.
Chez nous un changement d'architecture implique le 'system architect' et conduit à des changement bien plus profonds: pour le CPU ce sera changement du pipeline, du décodage, du jeu d'instruction, de l'ALU, ajout d'une FPU, etc.
Sur le Soc ce sera modifier l'interconnect/la matrice, rajouter de nouveaux master sur le bus, ajouter un nouveau DMA, faire du chiffrement à la volée, etc.
Enfin ce que je voulais dire initialement, c'est que souvent pour gagner de la puissance on se "contente" d'augmenter la fréquence et d'adapter ce qui doit l'être, plutôt que de changer drastiquement d'architecture (car de toutes façons on ne va pas réinventer ce que fait ARM à chaque fois, et que l'on paye très cher)...
@Scalp :
Oui c'est le chemin le plus "simple" que tu décris et qui est effectivement le plus courant.
Je suis surpris que le truisme que tu mets en avant puisse être contesté.
@awk
Si tu considères ça comme une banalité, alors tu n'y comprends absolument rien en architecture système des ordinateurs
@Scalp...
"En fait on diverge juste sur la notion de changement d'architecture.
Chez nous un changement d'architecture implique le 'system architect' et conduit à des changement bien plus profonds: pour le CPU ce sera changement du pipeline, du décodage, du jeu d'instruction, de l'ALU, ajout d'une FPU, etc."
Mais c'est bien de ça dont je voulais parler. Tu peux dire "Architecture système", c'est le terme que l'on utilise en français.
Mise à part l'overclocking qui consiste juste à augmenter l'horloge afin de gagner de la performance, dans le cas de l'A10 j'en doute.
En fait, quand je parle d'architecture d'un SoC (A10), je parle vraiment au niveau du SoC. Or si je ne me trompe, tu compares l'architecture au niveau du microarchitecture qui est base sur de l'ArmV8.
Mais dans le cas d'Apple, les Ax n'utilisent pas du tout l'architecture des cores Arm tel quel.
C'est un SoC, pour moi l'architecture est bien plus que le microarchitecture. Et il me semble que Apple a surtout pris la licence des jeux d'instruction et l'architecture des cores.
Le reste c'est l'équipe Apple dédiée au processeur qui l'a conçu. Il est très fort probable que le design final des cores soient totalement différents du design de référence ARM.
Ce qui pourrait expliquer pourquoi l'A10 qui n'a que 2+2 puisse être nettement plus performant que les big.LITTLE qui sont des 4+4.
Il ne faut pas oublier que Apple a racheté il y a quelques années la société PA-Semi qui est justement spécialisé dans le design de processeur.
@XiliX :
Juste pour faire le chieur : tu utilises ici overclocking par abus de langage
L'overclocking c'est utilisé un processeur au delà de son cadencement spécifié
Ce que tu décris n'est pas de l'overclocking ;-)
Pour le reste votre "désaccord" repose justement sur des enjeux de terminologie qui en étant un rien flou dans tes propos ouvre l'espace à trop d'interprétations
Il n'y a en fait pas de réelles oppositions dans vos vues si ont fait abstraction de la qualité de la formulation
@XiliX
Plusieurs points:
- Pardonne moi mes anglicismes. Par 'system architect' je voulais parler de l'architecte système, un gars (plus ou moins moche) dont le métier est justement de réfléchir à une nouvelle architecture répondant aux pré-requis, souvent dictés par un client ou alors par l'équipe application dans le cas d'Apple.
- Comme le dit awk, l'overclocking c'est dépasser la fréquence à laquelle le chip a été conçu. Donc là je ne te parle pas d'overclocking mais de concevoir un chip à une fréquence plus élevée lors de la synthèse et du placement et routage (APR).
- Apple a la license pour modifier le Cortex A53, ce qu'ils ont fait (modification du pipeline et autres). Mais le design du cœur ne peut pas être totalement différent, car mine de rien, le jeu d'instructions dicte pas mal l'architecture, et surtout car la base de l'A53 est déjà sacrément optimisée. Donc tu ne pourras pas modifier drastiquement ce cœur tous les ans pour espérer gagner en puissance. Par contre tu vas naturellement augmenter sa fréquence chaque année au passage sur une nouvelle techno, et en même temps adapter tout ce qui doit l'être dans le SoC.
- On peut également travailler chaque année sur la conso, mais souvent une optimisation du DVFS, des clock/power gating et des outils de backend suffisent (en plus du gain de conso dynamique apporté par la diminution de la finesse de gravure).
@calotype :
5 nm pardon, j'ai mal lu l'article.
@C1rc3@0rc
"Faut rappeler que l'avantage premier de la finesse de gravure c'est d'augmenter la rentabilité... du fondeur.
Plus on grave fin, moins y a de materiaux a utiliser, donc ça coute moins cher a produire..."
Là par contre on nage dans le très grand n'importe quoi !!!!!
Moi je veux bien la reduction du processeur...mais pour moi samsung rime avec explosion en ce moment donc je passerai mon tour tsmc c est bien aussi
@ancampolo :
Pffff ca n'a rien avoir ...
Vous êtes bien content que Samsung vous produisent vos cpu
Non moi ça me fait chier!
Dommage que Samsung n'ait pas pense à breveter le nom Fusion...
Il viennent de breveter explosion. Ils ont peur que la concurrence face comme eux et piquent leurs idées. Le soucis chez samsoule c'est qu'ils ne savent jamais si une idée est bonne ou pas, du coup ils inondent le marché de produits en tous genres en priant qu'il y en a qui trouvent leur public.
Pages