Exécuter un grand modèle de langage sur son iPhone, c’est déjà possible
En un an, le domaine des intelligences artificielles génératives a évolué de manière considérable. Non seulement ChatGPT n’est plus l’unique robot avec lequel vous pouvez discuter, mais en plus vous pouvez faire vivre ceux-ci sur vos propres appareils. Alors que nous vous avions expliqué au printemps dernier comment exécuter un grand modèle de langage sur votre Mac, il est depuis devenu possible de faire de même rien qu’avec votre iPhone.
Parmi les applications iOS du genre, il y a notamment MLC Chat, qui a l’avantage d’être gratuite et open source. L’application pèse pas moins de 3,3 Go car elle embarque par défaut Mistral 7B (« 7B » pour 7 milliards de paramètres), un modèle libre créé par la start-up française Mistral AI. L’intégration de Mistral 7B est intéressante, car ce modèle est globalement meilleur que Llama 2 7B, le modèle mis à disposition gratuitement par Meta (et disponible en option dans MLC Chat).
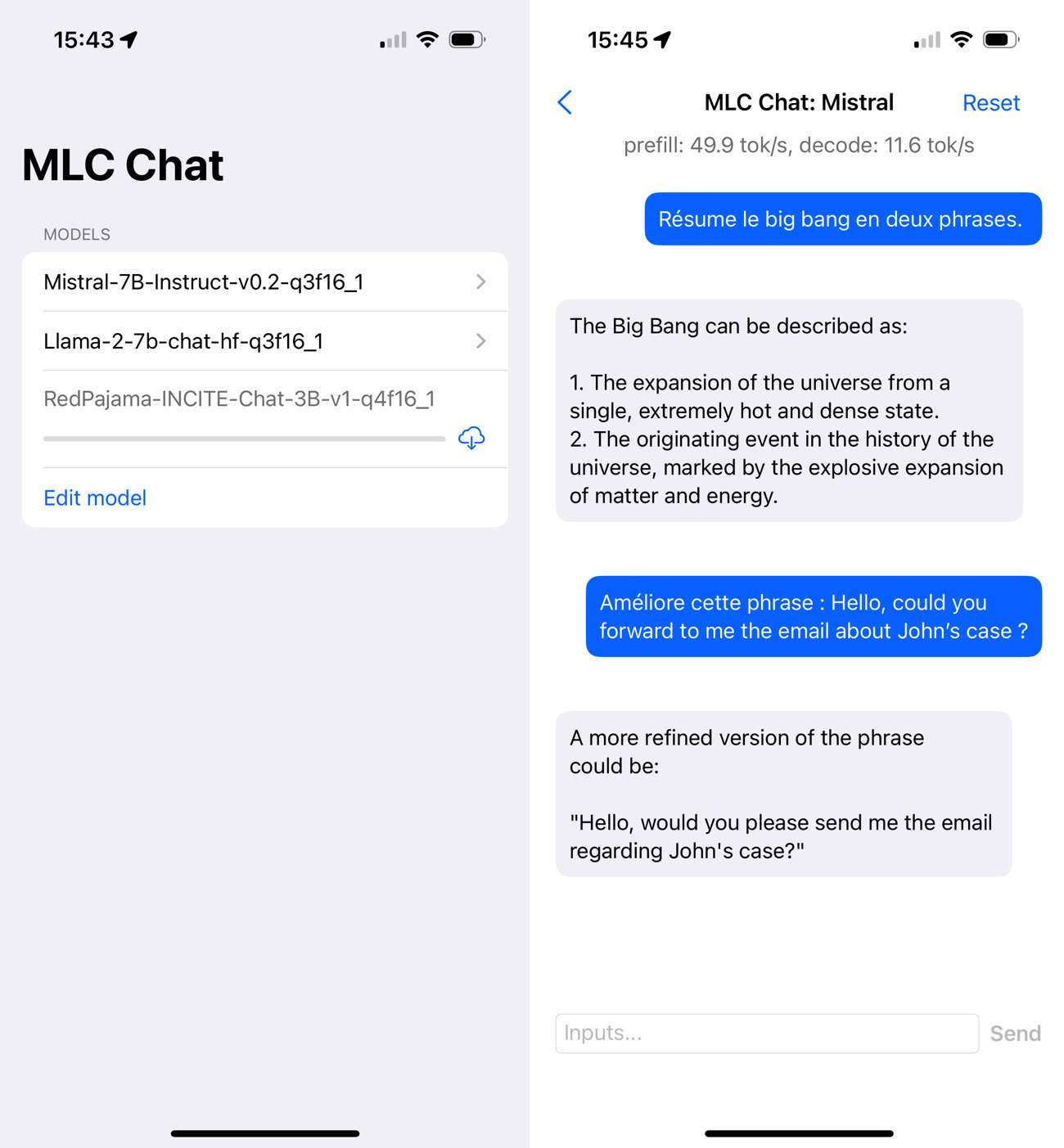
Grâce à MLC Chat, vous pouvez donc utiliser Mistral sans connexion internet. Vous pouvez lui poser toutes sortes de questions, lui demander de résumer un texte, lui faire traduire des phrases, etc. Par rapport à ChatGPT, les réponses mettent un peu plus de temps à arriver et elles sont généralement moins pertinentes — l’assistant a la fâcheuse tendance à privilégier l’anglais, entre autres choses.
L’utilisation de MLC Chat fait chauffer rapidement l’iPhone — un iPhone 15 Pro lors de mes essais —, signe que les calculs demandent beaucoup de puissance. L’éditeur de l’application recommande d’ailleurs un appareil avec au moins 6 Go de RAM pour Llama-7B. Tous ces inconvénients (lenteur relative, modèle moins perfectionné, forte consommation de ressources) font qu’il reste plus agréable d’utiliser ChatGPT, mais il faut bien mettre les choses dans leur contexte. Il y a d’un côté une IA générative propriétaire qui tourne sur de gros serveurs, de l’autre un modèle de langage ouvert exécuté par un iPhone.
Apple est en train de s’attaquer aux défauts actuels des IA génératives locales en développant ses propres technologies, du modèle de langage jusqu’à son cadre d’exécution pour, qui sait, créer un Siri moins bête.








Pour qui sait un Siri moins bête ? Que ça s’appelle Siri ou non. C’est une évidence qu’Apple va revoir son intégration des IA génératives dans ses téléphones. Je le dis depuis des mois, Apple sera la grande gagnante de l’ai car sa maîtrise logiciel et hardware est un avantage que très peu de monde possède. Dans un interview récent d’un fondateur de mistral il disait que la limite était la mémoire des gpu. Bien qu’ils ont levé 360m€ pour entraîner des modèles leur expertise c’est du bullshit contrairement aux personnes de chez Apple. Une bulle qui va exploser et en Europe on est les champions pour perdre de l’argent
@YosraF
Apple sera la grande gagnante de l’AI si elle sait l’intégrer et le moins qu’on puisse dire c’est qu’elle n’a pas prouvé grand chose (à part sa capacité à faire diversion avec Apple Vision Pro pour cacher la misère)
Ceci dit, elle a tellement d’argent qu’elle peut acheter sur étagère ce qu’elle ne sait pas faire, mais parfois c’est pas si simple d’intégrer
Bref ça reste encore un gigantesque point d’interrogation
Quant à Mistral, je te laisse la responsabilité de tes affirmations
@hugome
Je ne comprends pas trop ton commentaire. Justement le talent d’Apple c’est l’intégration et le lien étroit entre le software et l’hardware. Je pense que tu es mal renseigné car en juin 2023, des personnes de chez Apple ont livré une petite mises à jour qui ont amélioré de manière significative les performances de Stable Diffusion sur les processeurs M1/M2. Le papier récent pour utiliser la mémoire Flash au lieu d’utiliser des GPU à plus de 20 000€!
Ils peuvent acheter des modèles mais ils ont les ressources en interne et tous les papiers sont disponibles. Le modèle Ferret est déjà du multimodal qui « dépassent » selon le papier gpt4 vision. Le monde de l’open source a déjà fait des database d’entraînement open source et c’est le plus gros sujet pour entraîner des modèles.
Le chat c’est bien mais c’est une infime partie de la puissance des LLM. Couplé aux intents des apps comme l’a fait OpenAI avec les plugins etc, l’indexation des données. Si Apple arrive aller plus loin sur l’apprentissage en continu qu’aucune boîte n’a résolu à ce jour hormis du RAG limité. C’est Apple qui sera numéro 1
J’ai pu utiliser le modèle Mistral pour contrôler des interfaces graphiques à la voix sur les plateformes Apple. C’est assez génial.
Son défaut est en effet d’être uniquement anglais. Il faudrait une version optimisée pour le français.
@FloMo
En instruction quand tu lui demandes de parler en français il répond en français. En tout cas je teste l’application de l’article et j’ai des échanges en FR.
Quel logiciel as tu utiliser pour contrôler l’interface ? Le modèle n’est pas finetune pour avoir des sortis json strictes ?
@YosraF
Je n’ai pas utilisé cet outil. J’ai conçu ma propre app avec un portage de Llama.cpp en Swift. Ça fait le job.
L’outil : https://llmfarm.site
@FloMo
Ah super. Bravo pour le travail réalisé.
il y a quelques jours des commentateurs se moquaient de mistral qui avait disparu des radars, ben non en fait :)
@raoolito
Il est pourtant toujours autant cité un peu partout. Et ce d’autant plus avec le modèles médium multimodale 8x7B
@raoolito
Un mistral qui aurait fait pschiiit ?
Ou un mistral gagnant ?
😄
@DG33
😁👌🏽
Y a-t-il une configuration minimum d’iPhone (ou d’iPad) ?
@Giloup92
Pas de spécificité matérielle dans la fiche de l’app (sauf pour les Mac), mais minimum iOS 16.
@Giloup92
Pour Llama 2, c’est un iPhone avec 6 Go de RAM minimum, donc un iPhone 14 ou un iPhone Pro 12/13/14/15 au moins. Pour Mistral ce n’est pas précisé (j’ai testé avec un 15 Pro), mais c’est sans doute la même chose. Ces technos sont très gourmandes.
Merci pour l’info !
J’ai un 15Pro sur lequel j’ai installé cette app.
Je suis impressionné par la réactivité de Mistral en version 7B, alors oui ce n’est pas du GPT4 mais pour un LLM local et donc offline c’est impressionnant et réactif.
Alors j’imagine qu’Apple sera clairement en capacité de nous sortir un LLM sur iPhone en
Souhaitant que le 15Pro soit la configuration mini voir même un petit 14Pro histoire de rentré la bête accessible.
Une pensée pour ferret qui jette les bases des IA multimodales chez Apple et avec de l’espoir sur iOS.
Quelqu’un a réussi si à lancer mistral sur un iPhone 15 (6go de ram) ?
J’ai redémarré l’iPhone et j’ai quand même ce message :
Sorry, the system cannot provide 3814.7MB VRAM as requested to the app, so we cannot initialize this model on this device.
Pareil pour llama2 :
Sorry, the system cannot provide 3788.8MB VRAM as requested to the app, so we cannot initialize this model on this device.
Seul redpajama 3B se lance… mais plante à la première requête
@moua
iPhone 14 pro. Lancé sans souci.
Ça marche bien sur un 13 pro max 😀
@floflo une fois installé comment ça fonctionne svp ?
Apple n'aura pas besoin de faire d'annonce pour un SIRI dopé à l'IA ca se verra de suite 😏
Idem pour le correcteur d'orthographe et la suggestion
"L’éditeur de l’application recommande d’ailleurs un appareil avec au moins 6 Go de RAM pour Llama-7B."
Donc sur un iPhone, il suffit de 3 Go 🫢